Splunk and CMDB/CMS/IT4IT blog series part 1: Why should we bother?
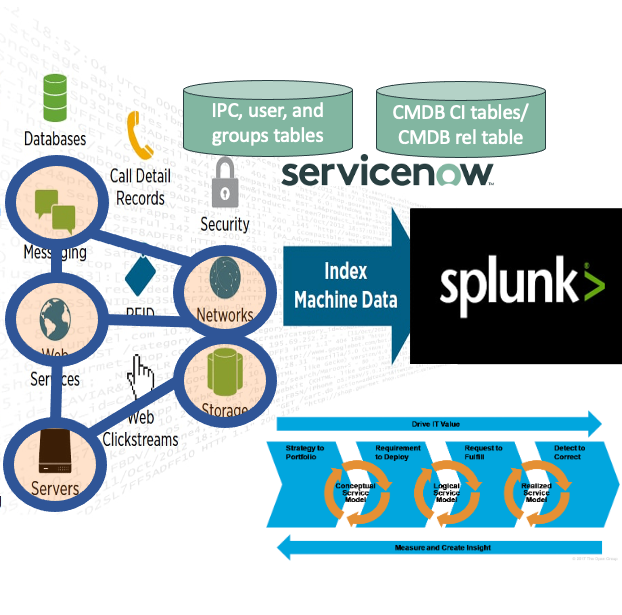
This is part 1 of a series of blogs about “Splunk and CMDB/CMS/IT4IT” where I want to share my quest for this subject.
For the readers of this blog series. When I talk about “IT4IT” I mean the service or digital product backbone and/or all other data objects.
Starting my career as 3rd line network support engineer I was attracted to why companies were facing performance and/or availability issues with their applications. Sometimes that had to do with bad configuration of the network’s equipment, sometimes bad software versions of network equipment but most often it had to do with the application developers not fully understanding the impact of (network) services on their application.
When I went on-site for such an issue I always questioned for maps or drawings and I questioned about the services impacted. Most of the networks were sort of caught in drawings but the question about which applications, services, or users were impacted often could not be answered. Later on, that missing information was part of the CMDB although there are still some companies struggling with the registration of that information. Even in the modern world with microservices or containers the registration of at least the services and the relationship to other services and users and owners should be registered in a CMDB or CMS. The rise of the IT4IT Reference Architecture by the Open Group (https://www.opengroup.org/it4it) is all about the lifecycle of services, or digital products as they are called now, and I see a lot of organizations looking into that. For the context of this blog I only look at the service/product model backbone of the IT4IT framework.
What CMDB/CMS/IT4IT have in common is that they fundamentally are based on data models that contain objects and their relations (content and context). For now, I’m not going to go deeper in this topic because I want to jump to the end-conclusions which is that CMDB/CMS will stay there and will contain valuable information where teams and the rest of the organization can make use of. For the newer world (microservices and containers) the underlying infrastructure is part of Observability suites and not perse within CMDB/CMS but the more “old-fashion” applications or server-based solutions should be. Ok so let us assume that there is some good information within CMDB/CMS, if not please contact us so we can be of help. In the next post, I want to explain why I want to call this CMDB/CMS/IT4IT thing the Common Metadata Data Model or in short CMDM.
Most often this CMDB/CMS data is only used within Service Management tooling and very rarely within Splunk. But luckily I build a CMDM solution that can collect, reconcile and visualize metadata in a common model from several other CMDB/CMS/CSDM systems. In this first version, I have build integration to ServiceNow CSDM and Splunk for analytics and visualization. Can it be used for other CMDB/CMS systems than ServiceNow or Splunk? Yes, please be in contact with us to discuss.
The quest I have is that I really like Splunk Enterprise for doing all sorts of smart things with machine-data. You can filter, aggregate, dashboard, alert, slice-and-dice, and Splunk even has IT Service Intelligence. That ITSI product is best used in the monitoring of services, and with services, I mean the services that are delivered to other parties in the organization or to (end)users. I do not mean perse the services as in micro-services. One could say I mean the services as in the service model backbone of IT4IT (ref: https://pubs.opengroup.org/it4it/refarch21/IT4ITv2.1.html#_Toc473282449).
It’s a little long introduction but I needed to set the scene first. And thinking about CMDB/CMS/IT4IT it became clear that an essential player in that market is ServiceNow. In the context of ServiceNow, we better can talk about Common Service Data Model (CSDM) as that data model is a CMDB framework that includes guidelines for using certain tables and relationships.
In the first follow-up post, I want to go deeper into why we (still) need such a CMDB/CMS/CSDM and the struggle with that subject. Let us, for now, assume that every organization needs at least content and context about the services or digital products they build and/or manage within their Business.
Why do we (still) need CMDB/CMS/CSDM
Well, I can be short of that: With all the great IT themes (cloud, micro-services, serverless, API’s, etc) that are happening, enterprise organizations still want to know: how are those IT services depending on each other, what is the impact of to other services, if one of them is failing where does it come from, etc. So even within the context of all the great IT themes, teams creating and operating those are still part of a bigger IT services landscape with tons of other IT Services and as such also other teams and people. Information about service health/state and dependencies with other services is crucial for more roles in the organization. And for some of those services, we need to have the information and relation about the underlying infrastructure and for some others, the underlying infrastructure is covered by Observability tooling and is not of interest to know centrally.
In the first follow-up post, I want to go deeper into why we (still) need such a CMDB/CMS/CSDM and the struggle organizations have with that subject. Let us, for now, assume that every organization needs at least content and context about the services or digital products they build and/or manage within their Business and as such is also important for some of the other toolings like Splunk Enterprise.
But as the term CMDB is seen as old fashion and CSDM is a ServiceNow thing I want to propose to call it a Common Metadata Data Model (CMDM). This because the CMDM is just bringing metadata together out of several CMDB’s/CMS’ses/cloud sources and IT4IT data model.
How is Splunk Enterprise handling CMDB/CMS/IT4IT content/context?
So let us dive a little deeper into how Splunk Enterprise is working with CMDB/CMS/IT4IT content and context.
Well, the short answer is that you can put every sort of data into Splunk. But that doesn’t mean is user-friendly in usage or easy to keep up to date.
The following image gives the four most used ways to handle CMDB/CMS/IT4IT content/context within Splunk.
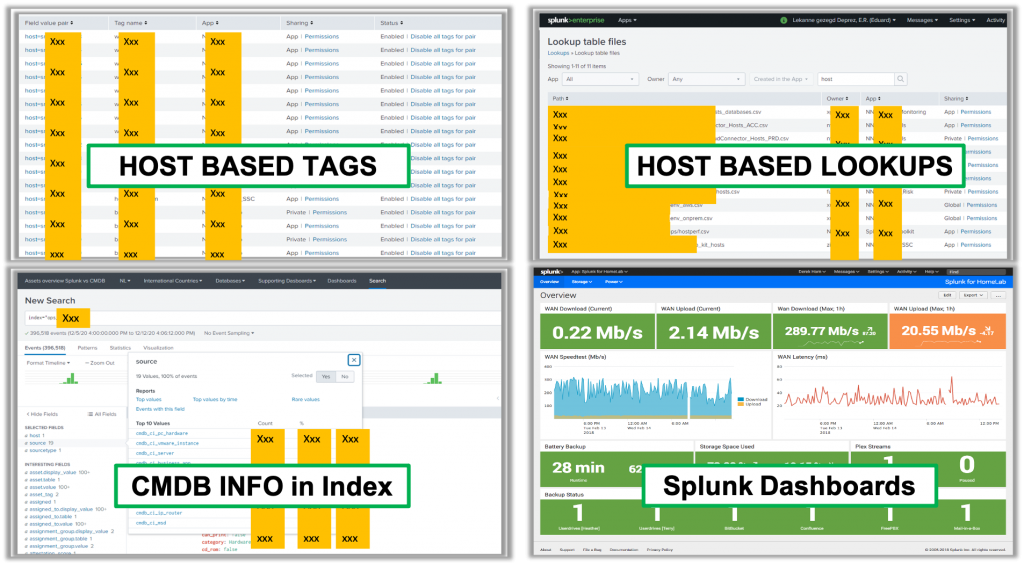
Don’t get me wrong those ways of doing within Splunk are great and flexible. But let me explain in the context of my quest. Splunk Enterprise is not based on a relational structure. So all things you do within Splunk are related but difficult to see in relation to each other. Meaning to see the relation between a Splunk dashboard and the tags that are used one has to go through each of the searches defined in that dashboard to find out. That is the reason why Splunk users use all sorts of functionality to achieve the relationships they want.
- Host-based tags: Within Splunk, you can define tags. Tags are based on any key=value combination within your data including the fields defined by Splunk itself. E.g. if host=”srv1234″ then assign tag=prod, or tag=”applicationY” to it. And no, you cannot assign tags at data ingest time, but rather at the time of data searching. These tags can then be used in searching the data. But if you have an enterprise setup and uses Splunk for Operations you probably will find hundreds if not thousands of tags that contain information that should come from CMDB/CMS. Because who is maintaining all those tags?
- Host-based lookups: Splunk lookups are very handy for enriching Splunk data with other data sorts of data. And sometimes I see that lookups are used to give more content for a host. E.g. for a certain host value presents the status (prod, acc, dev..) or even the application it belongs to. Again, who is going to maintain these lookups, and what about the rest of the service model like the service the applications belongs to, the other services it depends on, etc.
- CMDB info in index: This is what I see the most, inserting CMDB/CMS data into normal Splunk indices. It works, that is for sure. But what if you want to know the status of a particular CI how far back in time do you have to search to know that, or what if you want to know the servers that belong to a certain service. In other words, the relationship between those CI’s is often not there, and if it is there is not easy to use for average Splunk users.
- Splunk Dashboards: Creating Splunk dashboards is very easy, you just search for something, graph it, and then click save as dashboard or add it as an extra panel to an existing dashboard. But I also often see Splunk users having dashboards with fixed servers/applications in there. In other words, the CMDB/CMS content/context is hard-coded into these Dashboards. As being a Splunk admin for some time I often got the question of why parts of the dashboard were not populating with the right data and this is one of the causes. By the way, this is one of the reasons for making use of Splunk Tags or Eventtypes which making management easier.
I love working with Splunk and the ways I mentioned above are also good things and making life easier for Splunk users. But using them in the context of CMDB/CMS/IT4IT is what I feel is wrong or at least could be done better. And till now there wasn’t a good solution on Splunkbase that did that for you so if something was needed it became a custom build for your organization only.
I do see an increase in graph visualization interest within the Splunk arena. So now and then people share how they visualize linked data exposing things that were otherwise difficult to notice. I think the graphing part is indeed also needed but my vision is to have that linked data already linked and stored as such so that I can query on those links immediately.
How is Splunk ITSI handling CMDB/CMS/IT4IT content/context?

Splunk IT Service Intelligence (ITSI) is really a great product for monitoring the services and/or business processes in your organization. It doesn’t come with a CMDB or CMS because it is defined around the services and relationships are defined on a service. Yes, Splunk ITSI can import services, related services, and related entities from a file or Splunk search. But these imports do need to come in a certain structure that is not always easy to achieve. In other words, Splunk ITSI doesn’t come with a user-friendly, easy-to-adapt, functional CMDB/CMS/IT4IT integration or connection. By doing several Splunk ITSI implementation for large financial institutes it became clear that for those enterprises to work a good functional integration with CMDB/CMS is absolutely necessary.
Preview solutions architecture
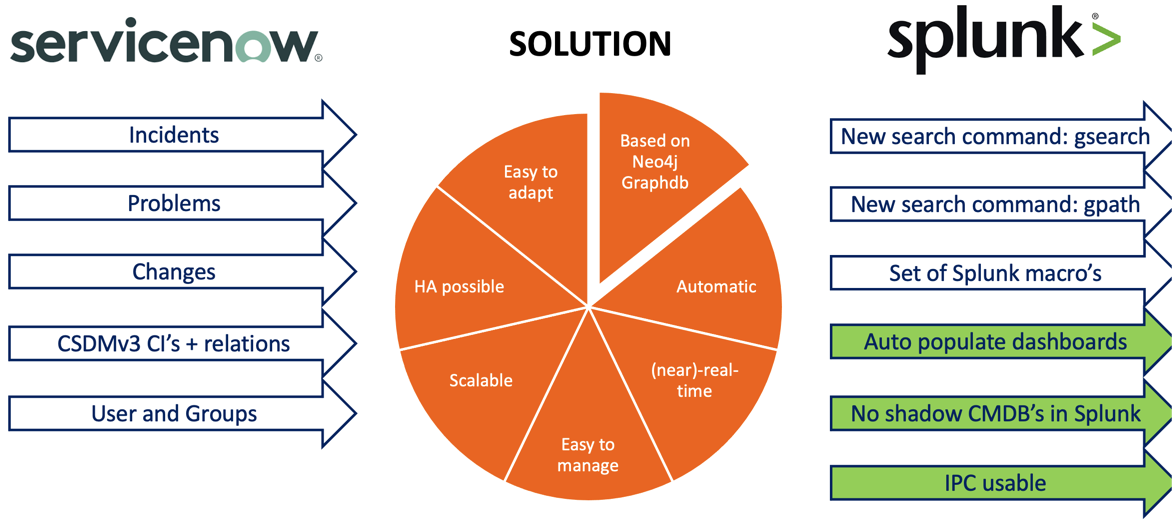
Here a preview of the solution’s architecture. Here the solution part is named Common Metadata Data Model (CMDM) and is closely located to the Splunk installation to minimize latency.
Subsequent blogs
In the subsequent blogs I want to cover the following:
- Do we still need a CMDB/CMS/CSDM?
- The functional explanation of my new CMDM solution initially started for Splunk and ServiceNow, what is there already on the market, and why I think Splunk should be involved.
- What does this CMDB/CMS/IT4IT data bring to you if the CMDM solution is in place and by using Splunk?
- Can the CMDM solution be used to improve the quality of CMDB/CMS?
- Can Splunk be used as a source for CMDM and if so how?
- What about CMDM and IT4IT?
- Can this CMDM solution help in improving and/or even speeding up the adoption of central CMDB/CMS and/or IT4IT?
If you want me to cover more topics or cannot wait for the other blogs to come please get in contact with me by going to the contact page, or visit us at our LinkedIn page:
Recent Comments